Updated: 2024-11-21 07:32:29 Pacfic
Deep Learning Scaling Law May Be Hitting A Wall - 7d
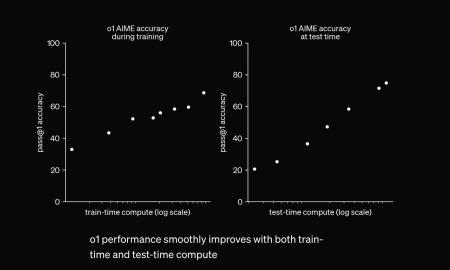
There is a consensus growing in the AI research community that the traditional ‘scaling law’ of deep learning might be reaching its limits. This law has been a driving force behind recent AI advancements, suggesting that simply increasing the amount of data, training time, and model parameters would lead to better performance. However, recent reports indicate that scaling has plateaued, with researchers struggling to create models that outperform OpenAI’s GPT-4, which is nearly two years old. One of the reasons behind this stagnation could be the exhaustion of high-quality training data. Supplementation with synthetic data is causing the new models to resemble older models, leading to problematic performance. Despite this, some researchers believe that alternative approaches like OpenAI’s ‘o1’ model, which focuses on extended ‘thinking’ time for tasks, might offer a way forward even if scaling plateaus.
References:
- EA Forum Bot Site - This Substack article discusses the possibility of deep learning hitting a wall and how Ilya Sutskever, co-founder of OpenAI, acknowledges scaling has plateaued. - 7d
- garrisonlovely.substack.com - Is Deep Learning Actually Hitting a Wall? Evaluating Ilya Sutskever's Recent Claims - 7d
- LessWrong - LessWrong also covers Ilya Sutskever's claims, analyzing the evidence for the scaling law plateau and potential implications. - 7d
Classification:
- HashTags: AI DeepLearning ScalingLaw
- Company: OpenAI
- Product: GPT-4
- Type: Research
- Severity: Major